Ransomware has become one of the most prominent threats in cyber-security and recent attacks has shown the sophistication and impact of this class of malware. In essence, ransomware aims to render the victim’s system unusable by encrypting important files, and then, ask the user to pay a ransom to revert the damage. Several ransomware include sophisticated packing techniques, and are hence difficult to statically analyse. In our previous work, we developed EldeRan, a machine learning approach to analyse and classify ransomware dynamically. EldeRan monitors a set of actions performed by applications in their first phases of installation checking for characteristics signs of ransomware.
You can download here the dataset we collected and analysed with Cuckoo sandbox, which includes 582 samples of ransomware and 942 good applications.
Further details about the dataset can be found in the paper:
Daniele Sgandurra, Luis Muñoz-González, Rabih Mohsen, Emil C. Lupu. “Automated Analysis of Ransomware: Benefits, Limitations, and use for Detection.” In arXiv preprints arXiv:1609.03020, 2016.
Please, if you use our data set don’t forget to reference our work. You can copy the BIBTEX link here.
Wireless Sensor Networks (WSNs) have become popular for monitoring critical infrastructures, military applications, and Internet of Things (IoT) applications.
However, WSNs carry several vulnerabilities in the sensor nodes, the wireless medium, and the environment. In particular, the nodes are vulnerable to tampering on the field, since they are often unattended, physically accessible, and use of tamper-resistant hardware is often too expensive.
Malicious data injections consist of manipulations of the measurements-related data, which threaten the WSN’s mission since they enable an attacker to solicit a wrong system’s response, such as concealing the presence of problems, or raising false alarms.
Measurements inspection is a method for counteracting malicious measurements by exploiting internal correlations in the measurements themselves. Since it does not need extra data it is a lightweight approach, and since it makes no assumption on the attack vector it is caters for several attacks at once.
Our first achievement was to identify the benefits and shortcomings of the current measurements inspection techniques and produce a literature survey, which was published in ACM Computing Surveys: V. P. Illiano and E. C. Lupu. ”Detecting malicious data injections in wireless sensor networks: A survey”, Oct. 2015 . The survey has revealed a large number of algorithms proposed for measurements inspection in sensor measurements. However, malicious data injections are usually tackled together with faulty measurements. Nevertheless, malicious measurements are, by and large, more difficult to detect than faulty measurements, especially when multiple malicious sensors collude and produce measurements that are consistent with each other.
We have designed an initial algorithm, which detects effectively malicious data injections in the presence of sophisticated collusion strategies among a subset of sensor nodes when a single event of interest (e.g. fire, earthquake, power outage) occurs at a time. The detection algorithm selects only information that appears reliable. Colluding sensors are not allowed to compensate for each other in the detection metric whilst still injecting malicious data thanks to an aggregation operator that is accurate in the presence of genuine measurements as well as resistant to malicious data. This work was published in IEEE Transactions on Network and Service Management, V. Illiano and E. Lupu, Detecting malicious data injections in event detection wireless sensor networks, Sept 2015
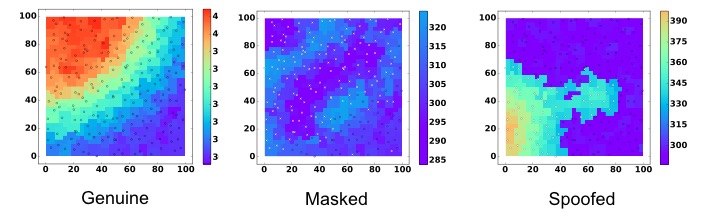
How many sensors does a malicious actor need to compromise to be successful? The white crosses in the middle diagram show these sensors when attempting to mask an event. The image on the right shows the sensors that need to be compromised to spoof an event. These diagrams are the result of an optimisation problem aiming to determine the worse possible attack. The method of determining the worst possible attack by solving an optimisation problem was published in IEEE Transactions on Sensor Networks Feb 2018 and provides a more general framework that allows to quantify the resilience gains obtained through detection algorithms or even to compare different detection algorithms.
Whilst detection proved highly reliable also in the presence of several colluding nodes, we have witnessed that more genuine nodes are needed to make a correct characterisation of malicious nodes. Hence, we have studied techniques to increase the reliability in identifying malicious nodes through occasional recourse to Software Attestation, a technique that is particularly reliable in detecting compromised software, but is also expensive for the limited computation and energy resources of the sensor nodes. Based on a thorough analysis of the aspects that make measurements inspection and software attestation complementary, we have designed the methods that allow to achieve a reliability as high as for attestation with an overhead as low as for measurements inspection. This work was presented at the 10th ACM Conference on Security and Privacy in Wireless and Mobile Networks (WiSec 2017).
In this paper we propose a modelling formalism, Probabilistic Component Automata (PCA), as a probabilistic extension to Interface Automata to represent the probabilistic behaviour of component-based systems. The aim is to support composition of component-based models for both behaviour and non-functional properties such as reliability. We show how addi- tional primitives for modelling failure scenarios, failure handling and failure propagation, as well as other algebraic operators, can be combined with models of the system architecture to automatically construct a system model by composing models of its subcomponents. The approach is supported by the tool LTSA-PCA, an extension of LTSA, which generates a composite DTMC model. The reliability of a particular system configuration can then be automatically analysed based on the corresponding composite model using the PRISM model checker. This approach facilitates configurability and adaptation in which the software configuration of components and the associated composition of component models are changed at run time.
Software systems are constructed by combining new and existing services and components. Models that represent an aspect of a system should therefore be compositional to facilitate reusability and automated construction from the representation of each part. In this paper we present an extension to the LTSA tool that provides support for the specification, visualisation and analysis of composable probabilistic behaviour of a component-based system using Probabilistic Component Automata (PCA). These also include the ability to specify failure scenarios and failure handling behaviour. Following composition, a PCA that has full probabilistic information can be translated to a DTMC model for reliability analysis in PRISM. Before composition, each component can be reduced to its interface behaviour in order to mitigate state explosion associated with composite representations, which can significantly reduce the time to analyse the reliability of a system. Moreover, existing behavioural analysis tools in LTSA can also be applied to PCA representations.
Building trustworthy systems that themselves rely on, or integrate, semi-trusted information sources is a challenging aim, but doing so allows us to make good use of floods of information continuously contributed by individuals and small organisations. This paper addresses the problem of quickly and efficiently acquiring high quality meta-data from human contributors, in order to support crowdsensing applications.
Crowdsensing (or participatory sensing) applications have been used to sense, measure and map a variety of phenomena, including: individuals’ health, mobility & social status; fuel & grocery prices; air quality & pollution levels; biodiversity; transport infrastructure; and route-planning for drivers & cyclists. Crowdsensing applications have an on-going requirement to turn raw data into useful knowledge, and to achieve this, many rely on prompt human generated meta-data to support and/or validate the primary data payload. These human contributions are inherently error prone and subject to bias and inaccuracies, so multiple overlapping labels are needed to cross-validate one another. While probabilistic inference can be used to reduce the required label overlap, there is a particular need in crowdsensing to minimise the overhead and improve the accuracy of timely label collection. This paper presents three general algorithms for efficient human meta-data collection, which support different constraints on how the central authority collects contributions, and three methods to intelligently pair annotators with tasks based on formal information theoretic principles. We test our methods’ performance on challenging synthetic data-sets, based on r eal data, and show that our algorithms can significantly lower the cost and improve the accuracy of human meta-data labelling, with a corresponding increase in the average novel information content from new labels.
Layered refinement with interleaved transformations
Refining policies from high level goals to enforceable specifications in asemi-automated and principled ways remains one of the most significant challenges in policy based systems. We have on two occasions attempted to tackle this challenges in collaboration with Dr Alessandra Russo at Imperial, Dr Arosha Bandara at the Open University and Dr Jorge Lobo at IBM. The first attempt wast done during the Dr Bandara’s PhD thesis. …
The Self-Managed Cell is an architectural pattern for building autonomous pervasive systems. It was developed in collaboration with Prof. Joe Sventek at the University of Glasgow, and with my colleagues Dr. Narnaker Dulay and Prof. Morris Sloman at Imperial College.
Ponder2 combines a general-purpose, distributed object management system with a Domain Service, Obligation Policy Interpreter, Command Interpreter and Authorisation Enforcement. The Domain Service provides an hierarchical structure for managing objects. The Obligation Policy Interpreter handles Event, Condition, Action rules (ECA). The Command Interpreter accepts a set of commands, compiled from a high-level language called PonderTalk, via a number of communications interfaces which may perform invocations on a ManagedObjectregistered in the Domain Service. The Authorisation Enforcement caters for both positive and negative authorisation policies, provides the ability to specify fine grained authorisations for every object and implements domain nesting algorithms for conflict resolution. …
Secure dissemination of data in crisis management scenarios is always difficult to achieve because network connectivity is intermittent or absent. In this work we have combined data-centric information protection techniques based on usage control, sticky policies and rights management with opportunistic networking to enable the dissemination of information between first responders in crisis management situations. The dissemination of keys for access to the information is controlled by a policy hierarchy that describes the permitted devolution of control. Policies are evaluated whenever two users are in proximity in the field and keys are distributed upon successful evaluation. Simulations with conservative mobility models show that the delay on information access i.e., the difference between the distribution of information and the distribution of keys remains small for realistic densities of users in the geographical areas.