Machine learning has produced a disruptive change in the society bringing both economic and societal benefits across a wide range of sectors. However machine learning algorithms are vulnerable and can be an appealing target attackers, who can inject malicious data to degrade system’s performance in a targeted or an indiscriminate way when retraining the learning algorithm. Attackers can also use machine learning as a weapon to exploit the weaknesses and blind spots of the system at test time, producing intentional misbehaviour. We are interested in understanding the mechanisms that can allow a sophisticated attacker to compromise a machine learning system and to develop new defensive mechanisms to mitigate these attacks. We are also interested in the development of new design and testing methodologies for more secure machine learning systems resilient to the presence of sophisticated attackers.
Universal Adversarial Perturbations in Evasion Attacks
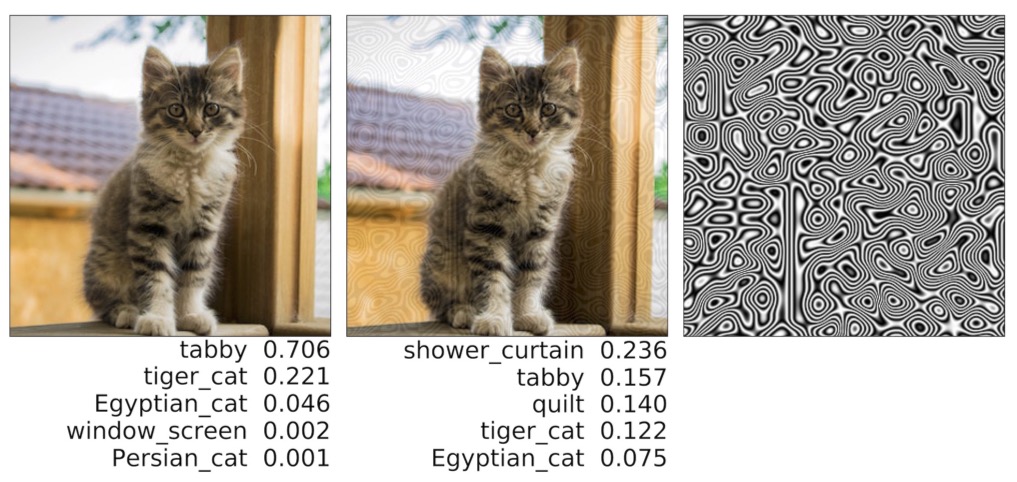
It is now well understood that many machine learning algorithms are vulnerable at run-time to adversarial examples, small perturbations to the input that cause misclassification or considerable variation in output. Such perturbations are most frequently calculated for each individual input separately. In contrast, we have focussed on Universal Adversarial Perturbations (UAPs), where the perturbations cause errors on a large part of the input set. Such perturbations are in our view more dangerous because they can be easily applied at scale to large parts of the input set.
Our first finding demonstrated that procedural noise such as Perlin noise acts as a UAP, and we have shown that it is possible using Bayesian Optimisation to build effective Black Box attacks that evade, image classification, image detection and image segmentation on very large numbers of inputs. (See also here for sensitivity to Gabor noise). This demonstrates a significant and systemic vulnerability of neural networks when processing images. The code for this study and the opportunities for trying it out are available from here. Some papers argued that DNNs primarily rely on texture so we have investigated the adversarial robustness of both texture and shape biased models to UAPs. Our findings show that shape-biased models are equally vulnerable to UAPs, but they are simply different UAPs.
The attack surface to adversarial examples is thus very large and this raises interesting questions about the effectiveness of techniques such as adversarial training, that can only patch this attack surface with training examples. Considering the observations above about the attack surface of adversarial examples we have focussed we believe that Jacobian Regularisation offers a promising and more systematic approach to increasing robustness to UAPs. Our early results suggest that Jacobian regularisation improves can improve robustness to UAPs in a comparable or better degree than adversarial training without sacrificing clean accuracy. We are also working on the vulnerability and sensivity of compressed machine learning models to adversarial attacks.
Stealthiness and Robustness in Poisoning Attacks
Poisoning attacks occur when an adversary can manipulate a part of the data used for training and does so with the objective of degrading the performance of the machine learning algorithm either in an indiscriminate or an error specific way. Such attacks are particularly dangerous for machine learning algorithms and increasingly common as the training data is often collected from IoT devices that can be easily compromised or from a supply-chain that may contain suppliers trusted to different extents. Our work in this area has focussed on understanding the effects of poisoning attacks and increasing the robustness of the training procedures to it. We have proposed new, more effective ways of computing optimal poisoning attacks. These play a significant role in understanding what an attacker can achieve and how vulnerable the algorithms are in the worst case scenario.

We have also shown that it is possible to train systems to automatically generate poisoning points with different levels of aggressiveness of the attack (i.e., detectability) and thus that it is possible to poison systems at scale. Finally, on the defensive side, we have shown that regularisation can help mitigate the effect of poisoning attacks provided that the hyper-parameters are adjusted to the aggressiveness of the attack. Choosing, fixed values for the hyper parameters either leads to insufficient robustness of the algorithm (when the values are too low), or damages the accuracy when there is no attack (when the values are too high). We have proposed formulations where the hyper parameters can be learnt and thus adapted to the attacks experienced.
Adversarial Aspects in Federated Machine Learning
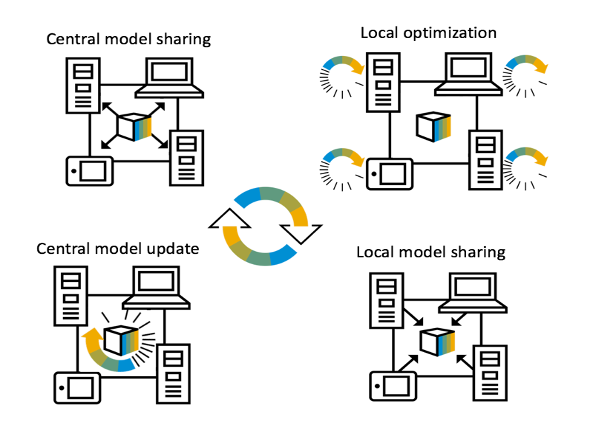
Federated learning enables training collaborative machine learning models at scale with many participants whilst preserving the privacy of their datasets. Standard federated learning techniques are vulnerable to Byzantine failures, biased local datasets, and poisoning attacks. We introduce Adaptive Federated Averaging, a novel algorithm for robust federated learning that is designed to detect failures, attacks, and bad updates provided by participants in a collaborative model. In contrast to existing robust federated learning schemes, we propose a robust aggregation rule that detects and discards bad or malicious local model updates at each training iteration.
This includes a mechanism that blocks unwanted participants, which also increases the computational and communication efficiency. Our experimental evaluation on 4 real datasets show that our algorithm is significantly more robust to faulty, noisy and malicious participants, whilst being computationally more efficient than other state-of-the-art robust federated learning methods such as Multi-KRUM and coordinate-wise median.