Exploiting contextual anomalies to detect perception attacks on cyber-physical systems
Zhongyuan Hau
Abstract
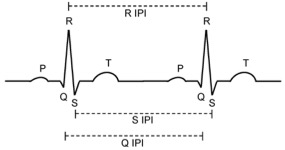
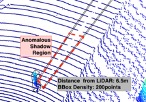
Perception is a key component in Cyber-Physical Systems (CPS) where information is collected by sensors and processed for decision-making. Perception attacks have been crafted specifically to subvert the CPS decision-making process. CPS are used in many safety-critical applications and perception attacks could lead to catastrophic consequences. Hence, there is a need to study how effective detection systems can be designed to detect such attacks. Designing detection systems for perception attacks in CPS is difficult as each CPS is domain-specific and existing detection systems for one CPS in one domain cannot be easily transferred to another. Current proposed detection systems are implemented to mitigate specific attacks and most offer only high-level insights on how the detection is performed. A systematic approach to designing detection for perception attacks that is generally applicable for CPS is needed. We propose a threat-modelling based methodology to design perception attack detection systems for CPS. An information model of the CPS, together with a threat model are used to determine how information correlations, defined as invariants, can be exploited as context for detecting anomalies. The proposed methodology was first applied to design perception attack detection Autonomous Driving, where we tackle the problem of attacks on LiDAR-based perception to spoof and hide objects. A novel specified physical invariant, the 3D shadow, was identified and shown that it is a robust verifier of genuine objects and was used to detect spoofed and hidden objects. Another learnt physical invariant of an object, where its motion needs to be temporally consistent, was shown to be effective in detecting object spoofing. Secondly, we apply the methodology to design the detection of false data injection in low-density sensor networks. We show that the use of learnt correlations across sensor measurements is effective even in a constrained setting with few sensors and heterogeneous data.